ChatGPT API 비용 폭증 막는 법: 토큰 비율로 손익분기점 잡기
ChatGPT API 비용은 입력·출력 토큰 비율과 모델 선택에 따라 같은 트래픽에서도 20배 넘게 갈리며, 손익분기점을 미리 잡으면 폭증을 막을 수 있습니다.
목차
- 결론: 트래픽을 늘리기 전에 입력·출력 토큰 비율로 손익분기점을 먼저 계산하고, 캐싱(최대 90% 할인)과 모델 선택으로 비용을 미리 통제하길 권장합니다.
- 하루 1만 건(입력 200·출력 300토큰) 기준 월 비용은 GPT-5.5 약 $3,000, GPT-5.4 $1,500, GPT-5.4 Mini $450, GPT-5.4 Nano 약 $125로 갈립니다.
- 응답 토큰이 입력보다 4~6배 비싸므로, 답변 길이 제한과 캐시 입력 활용이 가장 빠른 비용 절감 레버입니다.
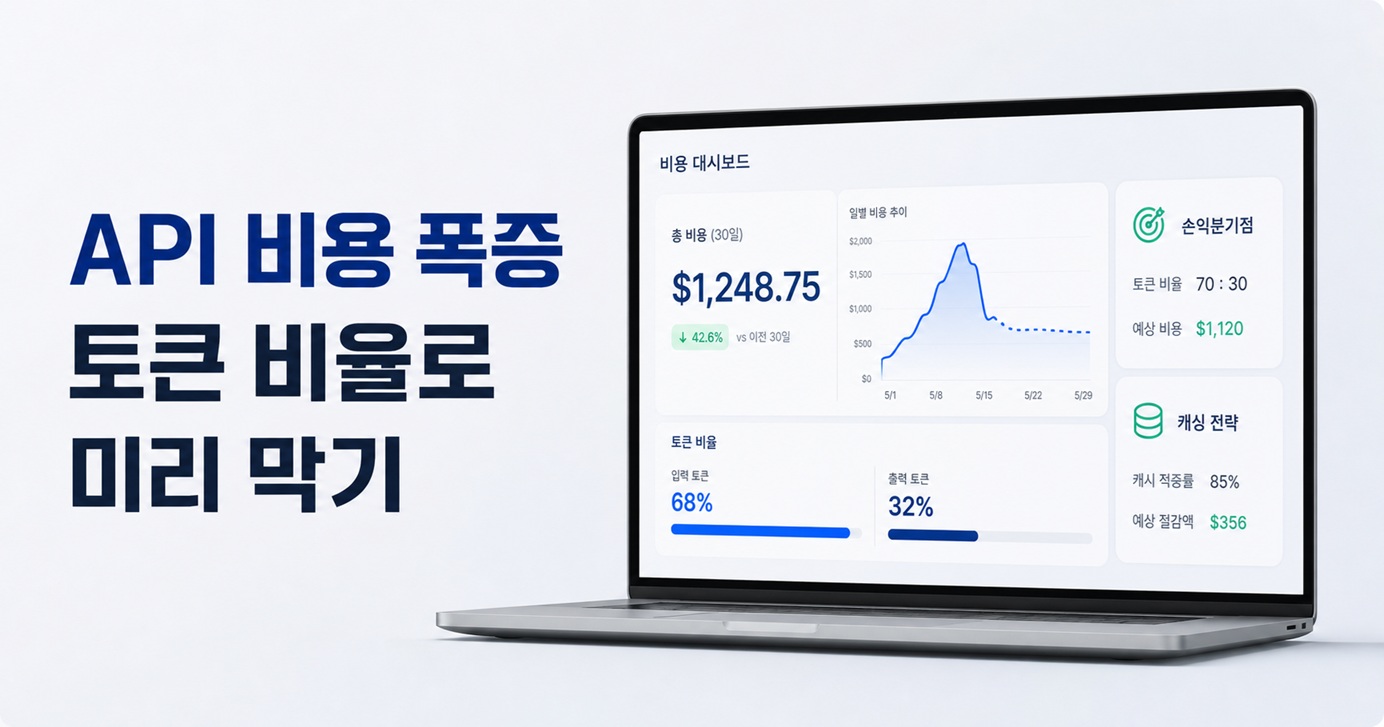
ChatGPT API는 호출 한 건이 아니라 토큰 단위로 과금되기 때문에, 트래픽이 선형으로 늘어도 비용은 모델 선택에 따라 전혀 다른 기울기로 증가합니다. 같은 하루 1만 건이라도 어떤 모델을 고르느냐에 따라 월 청구액이 $125에서 $3,000까지 벌어집니다.
그래서 핵심은 트래픽이 커지기 전에 입력·출력 토큰 비율을 기준으로 손익분기점을 미리 계산해 두는 것입니다. 이 글은 현행 OpenAI 요금 구조를 근거로 비용이 어디서 폭증하는지, 그리고 어떤 레버로 통제할 수 있는지 정리했습니다.
ChatGPT API 요금 구조는 어떻게 되어 있나요
ChatGPT API 요금은 입력 토큰과 출력 토큰에 각각 따로 매겨지는 이중 과금 구조입니다. 즉 프롬프트로 보낸 텍스트와 모델이 생성해 돌려준 텍스트가 별도 단가로 청구됩니다.
단가는 보통 토큰 백만(1M) 개당 달러로 표기합니다. 같은 모델이라도 출력 단가가 입력 단가보다 훨씬 높게 책정되어 있어, 답변이 길어질수록 비용이 빠르게 불어납니다.
현행 라인업의 입력·출력·캐시 입력 단가를 한 표로 정리하면 모델 간 격차가 한눈에 보입니다. 같은 물량을 처리해도 플래그십과 경량 모델의 비용 차이가 수십 배에 달합니다.
모델이 텍스트를 처리하는 최소 단위입니다. 영어 기준 약 4자, 평균 0.75단어가 1토큰에 해당합니다. 예를 들어 영어 200단어 답변은 대략 270토큰 안팎입니다.
트래픽이 늘면 비용이 어떤 위험을 만드나요
트래픽 자체가 비용을 폭증시키는 게 아니라, 통제되지 않은 설계 선택이 트래픽과 곱해지면서 청구액을 키웁니다. 위험 요인은 크게 네 가지로 나뉘며, 각각 대응책이 분명합니다.
특히 모델 과선택은 사고가 나기 가장 쉬운 지점입니다. GPT-5.4 Nano 입력 $0.20과 상위 모델 입력 $30.00을 비교하면 동일 물량 기준 150배까지 벌어집니다.
비용 통제가 가능하다는 신호는 무엇인가요
비용 폭증은 사실 통제 가능한 영역입니다. 코드 한 줄 바꾸지 않고도 설계 단계에서 적용할 수 있는 절감 레버가 여럿 존재하기 때문입니다.
- 캐시 입력 90% 할인 — 요청 앞부분의 일관된 시스템 프롬프트·참조 자료에 캐시가 적용되면, GPT-5.4 입력 단가가 $2.50에서 $0.25로 떨어집니다.
- 답변 길이 제한 40%+ 절감 — 답변을 150단어 이내로 제한하도록 지시하면 생성 토큰을 40% 이상 줄일 수 있습니다. 응답이 가장 비싼 항목이라 효과가 큽니다.
- 계층형 모델 60~80% 절감 — 요청 난이도에 따라 모델을 나누는 계층형 아키텍처는 단일 모델 대비 총비용을 60~80% 절감합니다. Standard에서 Mini로의 전환만으로도 약 70%가 줄어듭니다.
- Batch API 50% 절감 — 실시간 응답이 필요 없는 대량 작업은 Batch API로 처리하면 단가가 절반으로 떨어집니다. 사용량 한도 설정으로 상한도 함께 통제할 수 있습니다.
내 서비스에서는 어떻게 손익분기점을 계산하나요
손익분기점 계산은 의외로 단순합니다. 먼저 요청 한 건당 입력·출력 토큰을 측정하고, 일일 호출 수를 곱해 월 토큰 물량을 구한 뒤, 모델 단가를 대입하면 됩니다.
예를 들어 하루 1만 건(입력 200·출력 300토큰)이면 월 입력 60M·출력 90M 토큰입니다. GPT-5.4 기준 입력 $150 + 출력 $1,350 = 월 $1,500이 나옵니다. 같은 물량을 Nano로 돌리면 약 $125입니다.
이제 트래픽 규모대로 어떤 모델·전략을 택할지 분기하면 됩니다. 환경에 따라 다를 수 있지만 아래 기준이 출발점으로 안전합니다.
비용 폭증을 막으려면 무엇을 모니터링하나요
손익분기점을 한 번 계산했다고 끝이 아닙니다. 트래픽과 프롬프트는 계속 변하므로, 아래 항목을 정기적으로 들여다봐야 비용이 슬그머니 새는 것을 막을 수 있습니다.
- 월별 토큰 사용량 대시보드를 만들어 입력·출력 물량 추이를 추적합니다.
- 요청별 입력/출력 토큰 비율을 로그로 남겨, 출력이 비정상적으로 길어지는 구간을 잡아냅니다.
- 캐시 히트율을 모니터링해 캐싱이 실제로 적용되고 있는지 확인합니다.
- 모델별 비용을 분리 집계해 어떤 모델이 청구액을 끌어올리는지 식별합니다.
- 예산 임계값 알림을 설정해 월 한도의 일정 비율 도달 시 자동 통지를 받습니다.
- OpenAI 콘솔의 사용량 한도 잔액을 주기적으로 확인해 상한 초과를 사전 차단합니다.
자주 묻는 질문
Q. 토큰이 정확히 무엇인가요?
토큰은 모델이 텍스트를 처리하는 최소 단위입니다. 영어 기준 약 4자, 평균 0.75단어가 1토큰입니다. API 비용은 글자 수가 아니라 이 토큰 수로 계산되며, 입력 토큰과 출력 토큰이 각각 따로 과금됩니다.
Q. GPT-5.5와 GPT-5.4 Mini 중 어느 게 저렴한가요?
GPT-5.4 Mini가 훨씬 저렴합니다. 입력은 $5.00 대 $0.75, 출력은 $30.00 대 $4.50으로 약 6~7배 차이가 납니다. 고난도 추론이 꼭 필요한 게 아니라면 Mini로 충분한 경우가 많습니다.
Q. 캐싱은 어떻게 적용되나요?
요청 앞부분에 동일한 시스템 프롬프트나 참조 자료를 일관되게 두면 캐시 입력이 적용됩니다. 캐시 입력은 일반 입력 대비 최대 90% 할인되어, GPT-5.4 기준 $2.50이 $0.25로 떨어집니다. 매 요청마다 프롬프트 앞부분을 동일하게 유지하는 것이 핵심입니다.
Q. 출력 토큰이 왜 더 비싼가요?
응답은 모델이 한 토큰씩 순차적으로 생성하는 연산 비용을 반영하기 때문입니다. 모든 모델에서 생성 토큰이 입력 토큰보다 4~6배 비쌉니다. 그래서 답변 길이를 제한하는 것이 가장 효과적인 절감 방법 중 하나입니다.
Q. 비용 폭증을 막는 가장 빠른 방법은?
출력 길이 제한이 가장 즉효입니다. 답변을 150단어 이내로 지시하면 가장 비싼 출력 토큰을 40% 이상 줄일 수 있습니다. 이어서 반복 프롬프트에 캐싱을 적용하고, 작업 난이도별로 모델을 나누면 총비용을 60~80%까지 낮출 수 있습니다.