목차
올해 상반기에 금융 분석 AI 에이전트를 구축하면서 겪은 경험을 정리해봤어요. 설계부터 배포까지 약 6개월이 걸렸고, 그 과정에서 예상 못 한 문제도 꽤 있었습니다.
금융 데이터를 다루는 AI 시스템은 일반적인 웹 서비스와 다른 지점이 많더라고요. 특히 보안과 데이터 정합성 쪽에서 처음 생각했던 것보다 훨씬 많은 시간을 쓰게 됐습니다. 비슷한 프로젝트를 준비하는 분들이 참고할 수 있도록, 잘 됐던 부분뿐 아니라 실패했던 판단도 솔직하게 담았어요.
프로젝트 배경과 초기 판단
프로젝트 시작점은 단순했어요. 시장 데이터를 수집해서 분석하고, 특정 조건이 충족되면 알림을 보내는 시스템이 필요했습니다. 처음에는 "모놀리식으로 빠르게 만들고 나중에 분리하자"는 쪽으로 기울었는데, 결과적으로는 초기부터 마이크로서비스로 설계한 게 맞는 선택이었어요.
모놀리식을 포기한 이유는 크게 두 가지였습니다. 첫째, 데이터 수집과 분석 엔진의 스케일링 요구사항이 완전히 달랐어요. 수집은 I/O 바운드인데 분석은 GPU 연산이 핵심이라, 같은 서버에서 돌리면 리소스 낭비가 심해지는 구조였죠. 둘째, 금융 규제 때문에 데이터 접근 범위를 서비스 단위로 격리해야 했습니다. 모놀리식에서는 이게 코드 레벨 분리로는 한계가 있더라고요.
돌이켜보면: 마이크로서비스를 선택한 건 맞았지만, 처음부터 서비스를 너무 잘게 나눈 건 실수였어요. 초기에 7개로 쪼갰다가 서비스 간 통신 복잡도가 감당이 안 돼서, 결국 4개로 재편성했습니다. MVP 단계에서는 굵게 나누고, 운영하면서 필요한 시점에 분리하는 게 현실적이었어요.
아키텍처 설계와 기술 선택
최종 아키텍처는 마이크로서비스 4개를 중심으로 구성했어요. 각 서비스는 독립 데이터베이스를 두고, REST API와 Apache Kafka 메시지 큐로 통신하는 구조입니다.
핵심 설계 원칙: 각 마이크로서비스는 단일 책임 원칙을 따르고, 장애가 다른 서비스로 번지지 않도록 서킷 브레이커 패턴을 적용했어요. 금융 데이터 특성상 eventual consistency보다 strong consistency를 우선했습니다.
데이터베이스는 PostgreSQL을 메인으로 사용하고, 실시간 데이터 캐싱에는 Redis를 활용했어요. 시계열 데이터 비중이 큰 만큼 TimescaleDB 확장도 적용해서 조회와 집계 효율을 높였습니다.
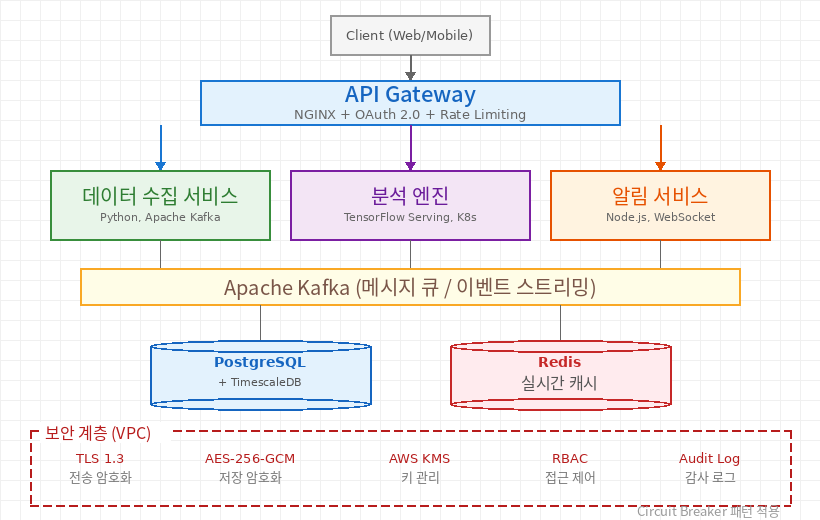
최종 아키텍처 구조도 — 초기 7개 서비스에서 4개로 재편성한 결과물
성능 최적화에서 삽질한 이야기
분석 모델의 추론 시간을 줄이기 위해 모델 양자화와 배치 처리를 도입했어요. TensorFlow Serving으로 모델을 서빙하고, GPU 클러스터에서 병렬 처리되도록 구성했습니다.
API 응답 시간 목표는 평균 150ms 이내였는데, 초기에는 350ms까지 튀는 경우가 잦았어요. 원인을 추적해보니 데이터베이스 쿼리가 아니라 서비스 간 네트워크 홉이 병목이더라고요. 처음에 서비스를 너무 잘게 나눈 대가를 여기서 치른 셈이었습니다. 서비스를 4개로 합치고, 캐싱 레이어를 추가하고, 커넥션 풀링과 인덱스 최적화를 병행하니까 그제서야 목표치 안에 들어왔어요.
데이터 보안 구현 방식
금융 데이터 보안은 프로젝트에서 가장 많은 시간을 잡아먹은 영역이었어요. "나중에 보안 붙이면 되지"라는 생각은 금융 도메인에서는 통하지 않더라고요. 다중 계층 방어 체계로 구성했고, 전송 구간과 저장 구간 모두 암호화를 적용했습니다.
- 전송 암호화: TLS 1.3 적용, Perfect Forward Secrecy 보장
- 저장 암호화: AES-256-GCM으로 데이터베이스 및 파일 시스템 암호화
- 키 관리: AWS KMS를 활용한 암호화 키 순환 및 분리 저장
- 인증: JWT 토큰 기반 인증, 토큰 만료 시간 30분 설정
- 감사 로그: 모든 데이터 접근 이력을 암호화하여 별도 저장
- 접근 제어: 역할 기반 액세스 제어(RBAC)로 서비스별 권한 분리
⚠️ 주의사항: 금융 데이터 처리 시에는 PCI DSS와 같은 업계 표준을 준수해야 합니다. 특히 카드 정보나 계좌 정보를 다루면 토큰화(Tokenization) 적용이 필수예요. 저희도 초기에 이 부분을 가볍게 봤다가, 보안 감사에서 지적받고 2주 분량의 추가 작업이 발생했습니다.
네트워크 보안은 VPC 내부 프라이빗 서브넷을 기준으로 설계했고, WAF(Web Application Firewall)로 외부 공격을 차단했어요. 내부 서비스 간 통신도 서비스 메시(Istio)로 암호화해서 방어층을 한 겹 더 뒀습니다.
데이터 마스킹 : 생각보다 까다로웠던 부분
개발·테스트 환경에서는 실제 고객 데이터 대신 마스킹 데이터를 사용해요. 개인 식별 정보는 해시 함수로 변환하고, 수치 데이터는 통계적 분포를 유지한 채 실제 값을 변경했습니다.
여기서 한 가지 실수가 있었는데, 초기에 마스킹 로직을 수동으로 관리했더니 새로운 필드가 추가될 때마다 누락이 생기더라고요. 결국 스키마 변경을 감지해서 자동으로 마스킹 규칙을 업데이트하는 파이프라인을 별도로 만들었어요. 로그 시스템에서도 정규식 기반 자동 마스킹을 구현해서, 디버깅 중에도 민감 정보가 평문으로 남지 않도록 했습니다.
개발 과정에서 만난 문제들
개발 초기에는 요구사항 정의와 데이터 파이프라인 설계에 가장 많은 시간을 투입했어요. 금융 데이터의 정확성과 실시간성을 동시에 만족시키는 구조가 핵심 과제였습니다.
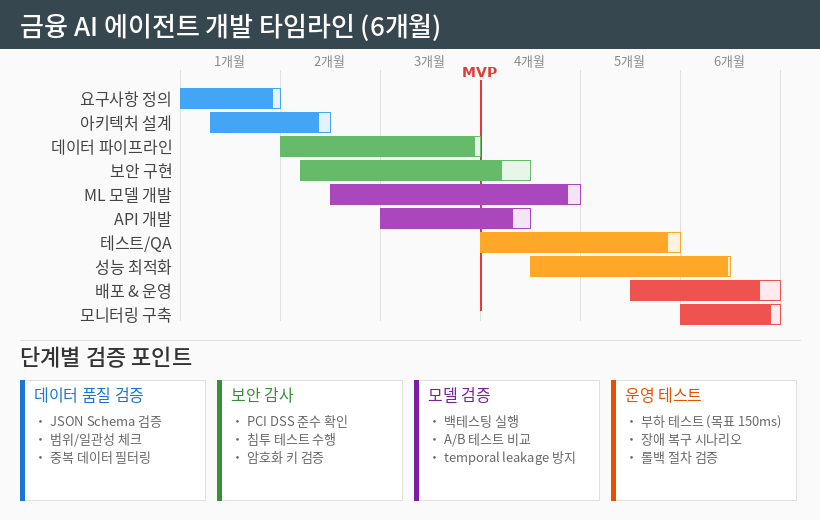
6개월간의 개발 타임라인 — 3개월 차에 MVP를 완성하고 이후 고도화를 진행
데이터 품질과의 싸움
금융 데이터는 누락이나 오류 하나가 크게 번지기 마련이에요. 한번은 데이터 소스 한 곳에서 타임존 표기 방식이 바뀌었는데, 그걸 못 잡아서 이틀치 분석 결과가 전부 어긋난 적이 있었어요. 그 이후로 데이터 검증 파이프라인을 본격적으로 구축했습니다.
- 스키마 검증: JSON Schema를 활용한 데이터 구조 검증 — 필드 누락이나 타입 불일치 즉시 감지
- 범위 검증: 수치 데이터의 최솟값·최댓값 경계 확인 — 비정상적인 가격 데이터 필터링
- 일관성 검증: 시간 순서 및 참조 무결성 확인 — 위에서 겪은 타임존 문제 방지
- 중복 제거: 동일한 시점의 중복 데이터 필터링 — 데이터 소스 장애 시 재전송 대응
데이터 품질 모니터링은 Prometheus와 Grafana 대시보드로 운영했어요. 지표가 임계값을 벗어나면 즉시 Slack으로 알림이 발송되도록 설정해서 대응 시간을 줄였습니다.
모델 학습에서의 함정: 시간 누수
머신러닝 모델은 시계열 데이터 특성을 반영해 LSTM과 Transformer 기반 모델을 조합했어요. 여기서 가장 조심해야 할 게 시간 누수(temporal leakage)인데, 쉽게 말하면 미래 데이터가 학습에 섞여 들어가서 백테스트 성능은 좋은데 실전에서는 망하는 현상이에요.
저희도 초기 모델에서 이걸 겪었습니다. 백테스트 성능이 비정상적으로 좋아서 의심했는데, 역시나 데이터 전처리 단계에서 미래 시점의 통계값이 피처에 포함되고 있었어요. 학습 데이터를 시간 순으로 엄격히 분할하고, 피처 엔지니어링 파이프라인에 시점 기준 필터를 추가해서 해결했습니다. 이후에는 A/B 테스트로 신규 모델과 기존 모델을 비교 평가하는 운영 프로세스도 갖추게 됐어요.
배포 환경 구축과 모니터링
배포는 Kubernetes 클러스터 환경에서 진행했어요. Blue-Green 배포 전략을 적용해 무중단 서비스를 유지하고, 문제 발생 시 즉시 롤백할 수 있게 구성했습니다.
모니터링 — 세 겹으로 나눈 이유
모니터링은 인프라·애플리케이션·비즈니스 로직, 이렇게 세 계층으로 나눠서 운영했어요. 처음에는 인프라 모니터링(CPU, 메모리)만 했는데, 그것만으로는 "서버는 멀쩡한데 분석 결과가 이상하다" 같은 비즈니스 레벨 문제를 잡을 수가 없었거든요.
- 인프라 메트릭: Prometheus + Node Exporter — CPU, 메모리, 디스크, 네트워크
- 애플리케이션 로그: ELK Stack (Elasticsearch, Logstash, Kibana) — 응답 시간, 에러율
- 분산 추적: Jaeger — 마이크로서비스 간 요청 흐름 추적, 병목 구간 파악
- 비즈니스 메트릭: 커스텀 대시보드 — 분석 정확도, 알림 발송 성공률, 데이터 수집 지연
- 알림 채널: Slack 연동(일반), PagerDuty(긴급) — 심각도에 따라 채널 분리
현재 운영 성과: 시스템 가동률 99.8% 이상을 유지하고 있고, 평균 API 응답 시간은 142ms 수준이에요. 자동 스케일링을 통해 트래픽 급증 상황(장 시작 직후 등)에서도 안정적으로 서비스하고 있습니다.
장애 대응을 위한 Runbook도 작성해뒀어요. 자주 발생하는 장애 시나리오(Kafka 컨슈머 랙 증가, Redis 메모리 부족, 모델 서빙 타임아웃 등)에 대해서는 자동 복구 스크립트를 적용했고, 야간이나 휴일에도 기본적인 운영 안정성은 유지되고 있습니다.
자주 묻는 질문
Q. 금융 AI 에이전트 개발에서 가장 어려운 부분은 뭐였나요?
데이터 품질 관리와 보안 요구사항 충족이 가장 까다로웠어요. 특히 실시간 데이터 처리에서 정확성과 응답 속도를 동시에 만족시키는 게 기술적으로 난도가 높았습니다. 성능 튜닝에만 전체 개발 기간의 20% 정도를 쓴 것 같아요.
Q. 왜 마이크로서비스를 선택했나요? 모놀리식이 더 빠르지 않나요?
초기 개발 속도만 보면 모놀리식이 확실히 빨라요. 하지만 금융 시스템은 서비스별 스케일링 요구사항이 다르고, 규제 때문에 데이터 접근 범위를 서비스 단위로 격리해야 했습니다. 다만 처음부터 너무 잘게 나누면 통신 오버헤드가 커지니, MVP에서는 굵게 나누고 점진적으로 분리하는 걸 추천해요.
Q. 운영비용은 대략 어느 정도 수준인가요?
구체적인 금액은 공개하기 어렵지만, AWS 인프라 비용이 전체의 약 60%를 차지해요. GPU 인스턴스와 데이터베이스 비용 비중이 가장 크고, Reserved Instance와 트래픽 연동 자동 스케일링으로 비용 효율성을 높이고 있습니다.
Q. 다시 시작한다면 뭘 다르게 하겠어요?
세 가지를 바꿀 것 같아요. 첫째, 마이크로서비스를 처음부터 잘게 나누지 않고 3개로 시작했을 거예요. 둘째, 보안 감사를 개발 중간이 아니라 설계 단계에서 미리 받았을 겁니다. 셋째, 데이터 마스킹 자동화를 첫 주에 구축했을 거예요. 수동 마스킹으로 시작했다가 나중에 자동화하느라 이중으로 시간이 들었거든요.
마무리: 돌아보며 느낀 것들
6개월간의 구축을 돌아보면, 가장 크게 느낀 건 금융 시스템에서는 "나중에 하자"가 통하지 않는다는 점이에요. 보안, 데이터 검증, 모니터링 이 세 가지는 처음부터 설계에 포함해야 하는 요소였습니다. 나중에 붙이려니 기존 코드를 뜯어고치는 데 더 많은 시간이 들더라고요.
기술적으로 잘 된 것도 있고, 판단을 잘못한 것도 있었어요. 초기에 서비스를 너무 잘게 나눈 것, 보안 감사를 늦게 받은 것, 데이터 마스킹을 수동으로 시작한 것 이런 실수들이 결국 일정을 밀리게 만들었습니다. 하지만 그 과정을 거치면서 팀의 금융 도메인 이해도가 많이 올라갔고, 다음 프로젝트에서는 훨씬 빠르게 움직일 수 있을 거라 생각해요.
앞으로는 모델 해석 가능성(Explainable AI)을 강화하고 실시간 온라인 학습 기능을 추가할 계획이에요. 금융 시장 변화에 더 빠르게 적응하는 시스템을 만드는 게 다음 목표입니다. 비슷한 프로젝트를 준비하시는 분들에게 이 글이 조금이라도 도움이 됐으면 좋겠어요.
'개발·프로그래밍' 카테고리의 다른 글
| ChatGPT for Sales, 지금 우리 영업팀에 도입할 가치가 있을까 (0) | 2026.05.06 |
|---|---|
| OpenAI API 직접 쓰던 팀이라면 AWS Bedrock으로 지금 옮겨야 할까 (0) | 2026.05.04 |
| 기존 DevOps 환경을 건드리지 않고 보안 자동화 구축하기 (0) | 2026.03.13 |
| Go 배포 후 느려진 서비스, context 취소 체인으로 1시간 내 병목 찾기 (0) | 2026.03.10 |
| 코딩 실력 늘리는 법 AI 시대 개발자 공부 방법 핵심 정리 (0) | 2026.03.09 |
