Claude Opus 4.8은 2026년 5월 28일 출시된 Anthropic 최신 모델로, AI Intelligence Index 149개 모델 중 1위를 기록했으며 코드 결함 무시 확률이 전작 대비 4배 감소해 정확성이 크게 향상됐습니다.

목차
- 결론: Claude Opus 4.8은 AI Intelligence Index 149개 모델 중 1위를 기록했으며, 코드 정확성과 에이전트 작업 성능에서 전작 대비 명확한 도약을 보여 주목할 만한 모델입니다(출시 당일 벤치마크 기준).
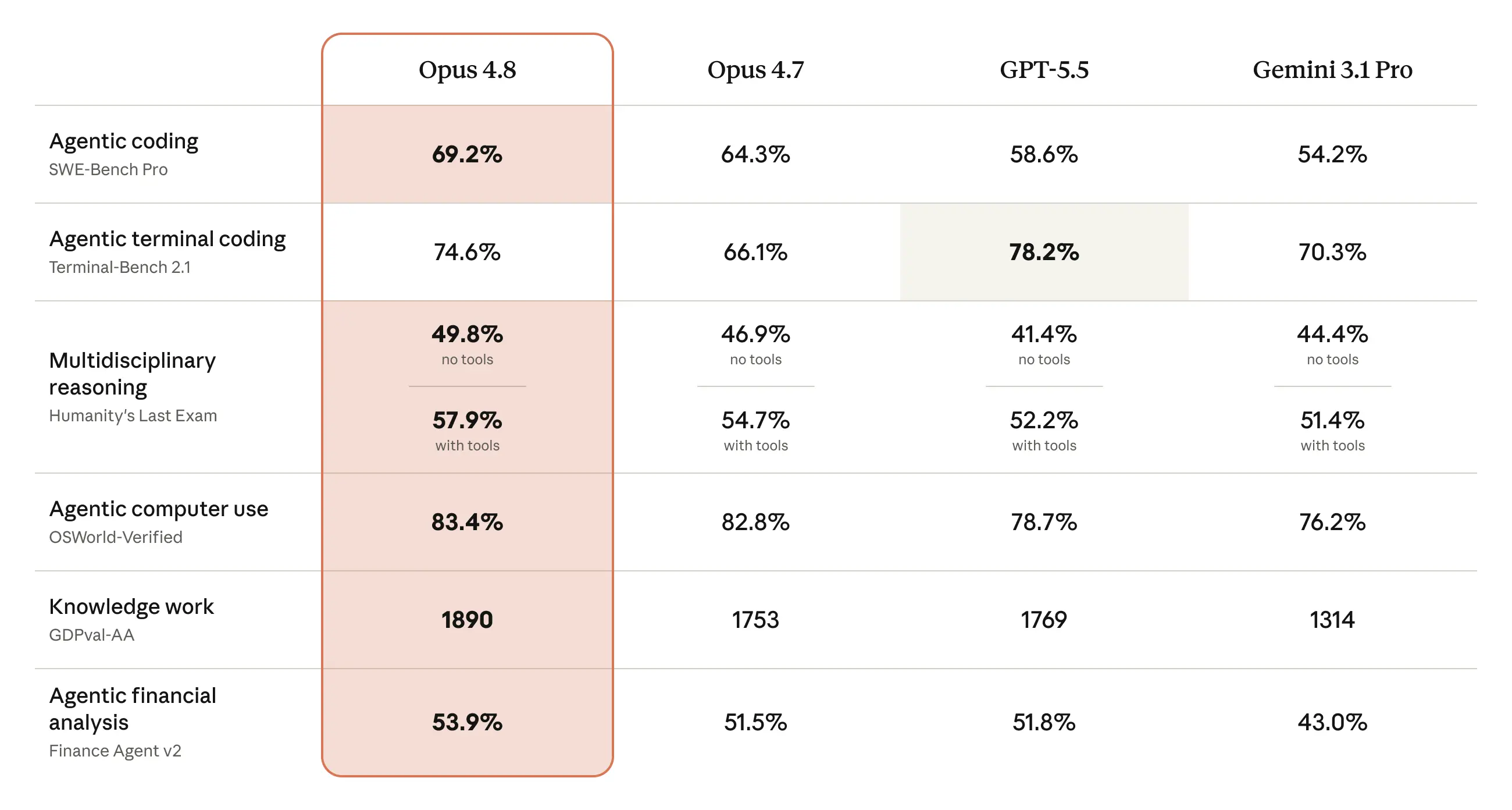
- SWE-bench Verified 88.6%, Online-Mind2Web 84%, Terminal-Bench 74.6% 등 주요 벤치마크에서 GPT-5.5와 Gemini 3.1 Pro를 앞질렀습니다(다수 매체 보도 기준).
- 가격은 Opus 4.7과 동일한 입력 $5/1M·출력 $25/1M이며, API ID는 claude-opus-4-8로 즉시 사용 가능합니다.
AI 벤치마크 평가 기관 Artificial Analysis의 Intelligence Index에서 149개 모델을 통틀어 1위를 차지한 모델이 2026년 5월 28일 공개됐습니다. Anthropic이 출시한 Claude Opus 4.8은 단순 성능 수치 개선에 그치지 않고, 코드 정확성과 에이전트 자율성이라는 실무 핵심 지표를 함께 끌어올렸다는 점에서 개발자와 기획자 모두가 주목할 만한 업데이트입니다.
이 글은 Anthropic 공식 발표와 Artificial Analysis의 독립 평가 데이터를 바탕으로, Opus 4.8이 전작과 어떻게 다른지, 벤치마크 수치가 실제로 무엇을 의미하는지 정리했습니다.
Claude Opus 4.8은 기존 모델과 무엇이 달라졌나요
가장 눈에 띄는 변화는 정직성 개선입니다. Opus 4.8은 자신이 작성한 코드에 결함이 있어도 지적 없이 통과시킬 확률이 전작 Opus 4.7 대비 약 4배 낮아졌습니다. 코드 리뷰를 AI에 맡기는 팀이라면 이 수치가 직접적인 품질 차이로 이어질 수 있습니다.
에이전트 기능도 크게 확장됐습니다. Claude Code에서는 수백 개의 병렬 서브에이전트를 동적으로 구성하는 워크플로우가 리서치 프리뷰로 제공되며, claude.ai와 Cowork에서는 effort control 기능으로 모델이 작업에 투입하는 연산량을 조절할 수 있습니다. 또한 Messages API에서 대화 중간에 system 메시지를 삽입하는 기능도 새롭게 추가됐습니다.
Legal Agent Benchmark의 all-pass 기준에서 처음으로 10%를 돌파한 모델이기도 합니다. 이 벤치마크는 복잡한 법률 문서 처리 에이전트 작업을 평가하는 지표로, 이전 모델들이 넘지 못했던 임계치를 Opus 4.8이 처음 통과했다는 의미입니다.
모델이 응답 생성에 투입하는 연산 자원의 양을 사용자가 조절할 수 있는 기능입니다. 빠른 답변이 필요한 간단한 작업에는 낮게, 정밀도가 중요한 복잡한 작업에는 높게 설정할 수 있습니다.
- 코드 결함 무시 확률 전작 대비 약 4배 감소 (정직성 개선)
- Claude Code 병렬 서브에이전트 수백 개 동적 워크플로우 (리서치 프리뷰)
- claude.ai / Cowork에서 effort control 지원
- Messages API 대화 중간 system 메시지 삽입 신규 지원
- Legal Agent Benchmark all-pass 기준 첫 10% 돌파
Claude Opus 4.8 벤치마크 수치는 어떻게 나왔나요
벤치마크 수치는 '모델이 얼마나 어려운 문제를 풀 수 있는가'를 객관화한 측정값입니다. 각 벤치마크가 평가하는 능력이 다르기 때문에, 수치를 올바르게 읽으려면 어떤 능력을 측정하는지 먼저 파악하는 것이 중요합니다.
SWE-bench Verified는 실제 GitHub 이슈를 AI가 코드로 해결하는 능력을 측정합니다. Opus 4.8은 88.6%를 기록해 전작 87.6%보다 높아졌으며, SWE-bench Pro(더 어려운 변형)에서는 69.2%로 전작 Opus 4.7(64.3%)보다 4.9%p 높았고 GPT-5.5(58.6%)·Gemini 3.1 Pro(54.2%)도 앞섰습니다(다수 매체 보도 기준).
Artificial Analysis Intelligence Index는 코딩·추론·수학·언어 등 복합 능력을 단일 점수로 환산하는 지표입니다. Opus 4.8은 61점으로 평가 대상 149개 모델 중 1위를 기록했습니다. Online-Mind2Web(웹 에이전트 탐색)에서는 84%를 기록해 Opus 4.7과 GPT-5.5를 모두 앞섰고, Terminal-Bench 2.1(터미널 명령어 실행)에서는 74.6%로 전작 66.1%에서 8.5%p 상승했습니다.
왜 지금 Claude Opus 4.8 얘기가 자주 나오나요
2026년 5월 28일 출시와 동시에 claude.ai 전 플랜(Enterprise·Team·Max)과 Anthropic API, Google Cloud Vertex AI, Microsoft Azure AI Foundry에서 사용 가능해졌습니다. 기존 Opus 4.7을 쓰던 팀이라면 API 모델 ID만 claude-opus-4-8로 바꾸면 되고, 가격은 입력 100만 토큰당 $5, 출력 100만 토큰당 $25로 전작과 동일합니다.
선택형 fast mode를 사용하면 입력 $10·출력 $50이지만, 이는 이전 세대 fast mode 대비 3배 저렴한 수준입니다. Artificial Analysis 추정 혼합 단가는 100만 토큰당 $4.10(7:2:1 비율 기준)이며, 캐시 적중 시 입력 비용이 $0.50으로 92% 절감됩니다.
컨텍스트 윈도우는 100만(1M) 토큰으로 A4 약 1,500페이지 분량에 해당합니다. 다만 Artificial Analysis 측정 결과 출력 속도는 초당 약 61.0 토큰으로 중앙값(62.2 t/s)보다 다소 느리고, 첫 토큰까지 지연(TTFT)은 21.69초로 중앙값 2.81초보다 높아 응답 시작이 늦은 편입니다. 단, 이 수치는 출시 직후 측정값이라 초기 인프라 부하가 반영됐을 수 있어 안정화 여지가 있습니다. 현재 측정 기준으로는 실시간 스트리밍보다 배치 처리나 에이전트 작업에 더 어울립니다.
Artificial Analysis 벤치마크 전체를 수행하는 동안 누적 출력 토큰이 1억 1천만(110M)에 달해, 동급 모델 평균(3,500만)보다 답변이 장황한 편으로 측정됐습니다(단일 응답이 아니라 평가 전 과정의 합계입니다). 상세한 설명이 필요한 작업에는 유리하지만, 비용 효율을 따진다면 응답 길이를 제어하는 설정을 함께 활용하는 것이 좋습니다.
- API 모델 ID: claude-opus-4-8
- 지원 플랫폼: claude.ai (Enterprise/Team/Max), Anthropic API, Google Cloud Vertex AI, Microsoft Azure AI Foundry
- 기본 가격: 입력 $5/1M 토큰, 출력 $25/1M 토큰 (Opus 4.7과 동일)
- Fast mode: 입력 $10/1M, 출력 $50/1M (이전 fast mode 대비 3배 저렴)
- 컨텍스트 윈도우: 1M 토큰 (A4 약 1,500페이지)
자주 묻는 질문
Q. Claude Opus 4.8 API를 사용하려면 어떻게 해야 하나요?
Anthropic API 키를 보유하고 있다면 모델 ID를 claude-opus-4-8로 지정하면 됩니다. 기존 claude-opus-4-7을 사용하던 코드에서 모델명 문자열 하나만 바꾸면 되며, 가격도 동일하므로 추가 비용 없이 전환할 수 있습니다. Google Cloud Vertex AI나 Microsoft Azure AI Foundry를 사용하는 경우에도 해당 플랫폼에서 같은 모델명으로 접근 가능합니다.
Q. Claude Opus 4.8과 GPT-5.5 중 코딩에는 어느 쪽이 더 낫나요?
다수 매체 보도 기준으로 SWE-bench Pro에서 Opus 4.8이 69.2%, GPT-5.5가 58.6%를 기록해 코드 수정 작업 기준으로는 Opus 4.8이 앞섰습니다. 또한 Opus 4.8은 코드 결함 무시 확률이 전작 대비 4배 감소해 정확성이 높아진 점도 특징입니다. 다만 응답 시작까지 지연이 21초 내외로 길기 때문에 빠른 대화형 코딩 보조가 필요하다면 속도 특성도 함께 고려해야 합니다.
Q. Claude Opus 4.8의 1M 토큰 컨텍스트는 실제로 얼마나 긴 내용인가요?
100만 토큰은 A4 용지 약 1,500페이지 분량에 해당합니다. 긴 코드베이스 전체, 대규모 법률 문서 묶음, 또는 수백 개의 회의록을 한 번에 처리할 수 있는 용량입니다. 다만 컨텍스트가 길어질수록 처리 비용도 늘어나므로, 실제 업무에서는 필요한 범위만큼 선택적으로 활용하는 것이 효율적입니다.
Q. Claude Opus 4.8의 응답 속도가 느리다는데 문제가 되나요?
Artificial Analysis 측정 기준으로 첫 토큰까지 지연(TTFT)이 21.69초로 중앙값(2.81초)보다 높은 편입니다. 다만 출시 직후 측정값이라 초기 인프라 부하가 반영됐을 수 있어 며칠 뒤 안정화될 여지가 있습니다. 현재 수치 기준으로 대화형 챗봇이나 실시간 코드 제안처럼 빠른 응답이 중요한 용도에는 단점이 될 수 있지만, 배치 문서 분석·에이전트 워크플로우·대규모 코드 리뷰처럼 품질이 우선되는 작업에서는 크게 문제되지 않습니다. fast mode 옵션을 사용하면 속도와 비용 간 트레이드오프를 조절할 수 있습니다.
Q. Claude Opus 4.8은 어떤 플랜에서 사용할 수 있나요?
claude.ai에서는 Enterprise, Team, Max 플랜에서 사용 가능합니다. 개발자라면 Anthropic API를 통해 직접 접근할 수 있으며, 기업 클라우드 환경에서는 Google Cloud Vertex AI와 Microsoft Azure AI Foundry도 지원됩니다. 무료 플랜이나 Pro 플랜에서의 지원 여부는 Anthropic 공식 페이지에서 확인하는 것을 권장합니다.
'테크 이슈' 카테고리의 다른 글
| Claude 요금제 변경 정리: Pro 20달러인데 추가 요금이 나오는 이유 (0) | 2026.05.24 |
|---|---|
| Google I/O 2026 핵심 발표 총정리: 개발자 워크플로가 바뀌는 7가지 (0) | 2026.05.23 |
| Claude Code UI 모르면 손해 — 재설계 후 달라진 세션 관리 핵심 정리 (0) | 2026.05.13 |
| Claude Code를 떠나 GPT Codex로 옮기는 개발자들, 그 이유는 무엇인가 (0) | 2026.05.11 |
| GPT-5.5 Instant, Gmail·과거 채팅까지 참고한다 — 개인화 기능 완전 해부 (0) | 2026.05.08 |



